
Revolutionizing Audio Asset Creation Through Neural Network Synthesis
The intersection of artificial intelligence and creative arts has fundamentally altered how digital assets are conceptualized and produced. For decades, the barrier to entry for high-quality music production was defined by the need for extensive theoretical knowledge, expensive instrumentation, and complex recording environments. This traditional model often left content creators, marketers, and developers reliant on generic stock libraries that rarely aligned perfectly with their specific narrative needs. The emergence of the AI Song Generator represents a significant shift in this paradigm, offering a sophisticated mechanism to convert raw textual descriptions into fully arranged musical compositions. By leveraging deep learning algorithms, this technology allows for the rapid prototyping and final production of audio tracks that are tailored to precise emotional and stylistic requirements.
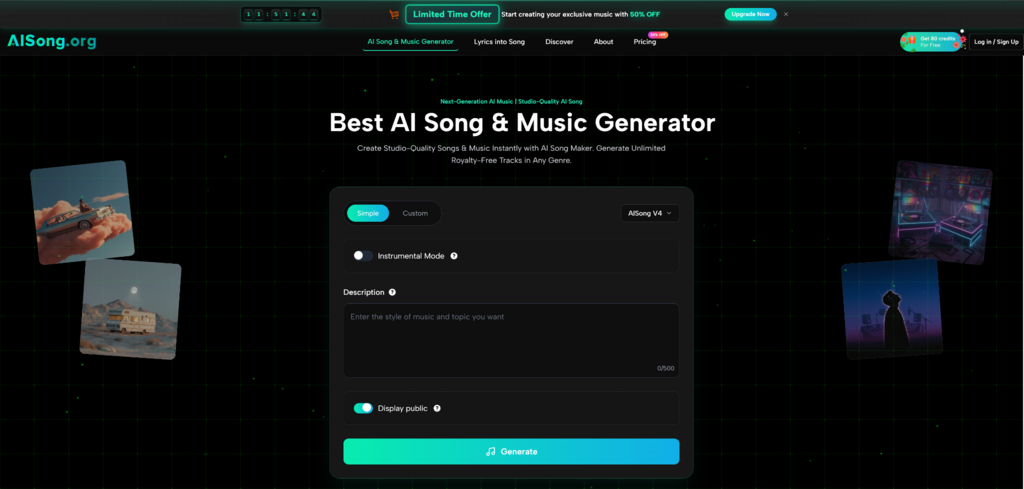
Deconstructing The Text To Music Synthesis Process
The core value proposition of this platform lies in its ability to bridge the gap between semantic language and auditory output. Unlike simple MIDI generators of the past, modern neural networks analyze the nuances of natural language prompts to determine the appropriate instrumentation, tempo, and harmonic structure. When a user inputs a prompt such as “energetic electronic dance music for a fitness video,” the system does not merely retrieve a file; it constructs a new audio waveform based on learned patterns of the genre.
Interpreting Semantic Descriptors For Genre And Mood
In my analysis of the generation engine, the system demonstrates a capability to process multi-dimensional inputs. It appears to weigh various descriptors—genre (e.g., Pop, Classical, Hip-hop), mood (e.g., Happy, Melancholic), and even specific instrumental textures—to create a cohesive track. This “understanding” of musical theory allows the AI Song Maker to make compositional decisions regarding chord progressions and rhythmic patterns that would typically require a human composer’s intuition. The result is a piece of music that feels structurally sound and stylistically consistent with the user’s initial vision.

Synthesizing Vocal Tracks From Textual Inputs
A distinguishing feature of this technology is its capacity to handle lyrical content. The platform integrates a text-to-speech synthesis engine that is tuned specifically for musical performance. This allows users to input their own lyrics, which the AI then fits to a melody it generates. The alignment of syllables to musical beats—a process known as prosody—is handled automatically. While the emotional range of synthetic vocals is still an area of active development, the current iteration provides a surprisingly effective tool for creating demo tracks or background vocals where a human singer is not available or cost-prohibitive.
Leveraging Automated Lyric Generation Capabilities
For users who lack lyrical expertise, the platform includes an auxiliary AI Lyrics Generator. This tool can draft verses, choruses, and bridges based on a central theme, further streamlining the creative process. By combining this text generation with the music synthesis engine, the system offers a complete end-to-end solution for song creation, effectively functioning as a virtual co-writer and producer.
Operational Workflow For Generating Custom Musical Pieces
The user experience on the platform is designed to be linear and accessible, stripping away the complexities of a Digital Audio Workstation (DAW). Based on the documented process, the workflow is condensed into three primary stages.
Articulating The Creative Vision Through Text
The process begins with the user defining the parameters of the composition. In the provided text interface, users describe the style, mood, and genre they wish to emulate. This stage is critical as it sets the foundational variables for the algorithm. Users can be as specific as “melancholic jazz for a rainy scene” or leave the prompt broader to allow the AI more creative freedom. This step also involves inputting or generating the lyrics if the track is intended to have vocals.
Algorithmic Processing And Pattern Analysis
Once the prompt is submitted, the AI initiates the generation phase. During this step, the underlying neural networks analyze the input data and cross-reference it with vast datasets of musical patterns. The system composes original melodies, harmonies, and rhythms in real-time, tailoring the output to the specifications defined in the first step. This computational process replaces the traditional recording and mixing phases, delivering a finished product in a fraction of the time.
Acquiring The Final Asset For Distribution
The final stage involves the retrieval of the generated audio. The platform allows users to download their unique creations in high-quality MP3 format. Crucially, these downloads are accompanied by full commercial rights, meaning the user can immediately integrate the music into commercial projects, social media content, or broadcast media without the need for further licensing negotiations or attribution.
Comparative Evaluation Of Music Creation Methodologies
To better understand the strategic advantage of using an AI-driven platform, it is useful to compare it against traditional methods of acquiring music. The following table outlines key differences in resource allocation and asset control.
| Evaluation Metric | Custom Human Composition | Stock Music Libraries | AI Algorithmic Generation |
| Turnaround Time | High (Days to Weeks) | Medium (Hours of searching) | Low (Minutes) |
| Cost Structure | High (Professional fees) | Medium (Subscription/License fees) | Low (Freemium/Credit-based) |
| Asset Exclusivity | Unique to the client | Non-exclusive (Used by many) | Unique generation per prompt |
| Creative Control | High (Iterative feedback) | Low (Fixed pre-made tracks) | High (Prompt-based iteration) |
| Copyright Complexity | High (Contracts required) | Medium (Platform specific rules) | Low (Royalty-free included) |
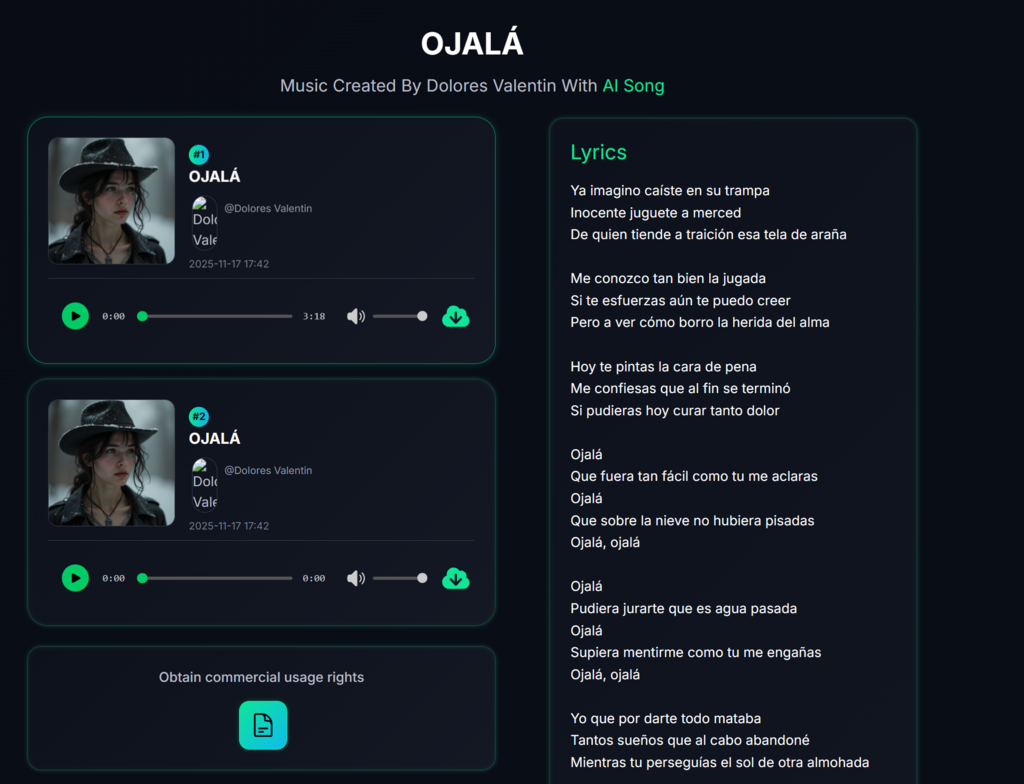
Technical Observations On Audio Fidelity And Commercial Viability
While accessibility is a major driver for adoption, the technical quality of the output remains paramount for professional use. The platform states that it produces audio at a 44.1kHz sample rate, which is the industry standard for CD-quality audio. This level of fidelity ensures that the tracks are suitable for use in high-definition video productions and streaming platforms.
Assessing The Studio Quality Claims And Output Formats
In practical application, the “studio quality” claim holds up well for background music and electronic genres where synthetic textures are commonplace. The clarity of the mix—specifically the separation between vocals and instrumentation—is generally high. Furthermore, the inclusion of post-production tools such as a Vocal Remover and MP3 to WAV converter indicates that the platform is built to support broader production workflows. These utilities allow creators to isolate stems for remixing or convert files for lossless editing, adding a layer of professional utility beyond simple track generation.
Navigating Copyright And Commercial Usage Rights
Perhaps the most significant feature for businesses is the clear stance on intellectual property. The platform explicitly states that all generated tracks are royalty-free and come with full commercial license ownership. This effectively removes the legal friction often associated with using music in marketing. By ensuring that users own the rights to the AI-generated content, the platform provides a safe harbor for creators who need to monetize their content on platforms with strict copyright enforcement, such as YouTube or Twitch.




